会社組織で IT をしていると、Linux や FreeBSD などの UN*X 系の OS だけではなく、一般ユーザが使いやすくするために Windows を使っていることが一般的であることがほとんどです。私の会社でもご多分に漏れず、一般ユーザは Windows クライアントで日常業務を、管理者は Windows サーバ、や Linux、 FreeBSD 等の、自分の管理対象に適した OS を使用していました。私の場合も、FreeBSD などを自分の PC で動かして X11 で日本語を使う程度で事足りているはずだったのですが、メールは Outlook だ!作文は Word だ!表計算は Excel だ!プレゼンテーションは PowerPoint だ!などと言われてしまうと、Windows クライアントの方が日常生活が楽になることから Windows を使っていました 🙁
大学を出てすぐのころは今の様に M$ に占拠されている状況ではなかったので、FreeBSD で X11 を動かしてほとんどのことは FreeBSD 上で済ませて、Windows が必要な時は FreeBSD に Linux エミュレータを入れて、そのうえで Linux 用の VMware を動かして、さらにその上で Windows を動かしていた記憶があります。そのころの記憶を頼りに FreeBSD を普段使いの Windows の様に使う方法をご紹介します。
X11 のアプリケーションを X11 として使用するには X11 サーバーをどこかで起動させる必要があるのですが、ここまで Windows が蔓延っている状況だと、Windows 上で X11 サーバーを動かしてしまう方法もあります。この場合だと、グラフィックドライバーの調整などはスキップできてしまいますし、日本語入力も X11 プロトコルに依存せず M$ IME を使用することができます。ここでは、X11 サーバーも FreeBSD が動いている同じ PC で動いている場合を想定しています。
まず FreeBSD で X11 を使用するためには xorg でまとめられている基本的なソフトウェアをまずインストールします。libX??? のライブラリ、 x??? の X11 で使用される基本的なコマンド類や、各種フォントがインストールされます。前提として、息をするために必要なソフトウェアは既にインストール済みとします。
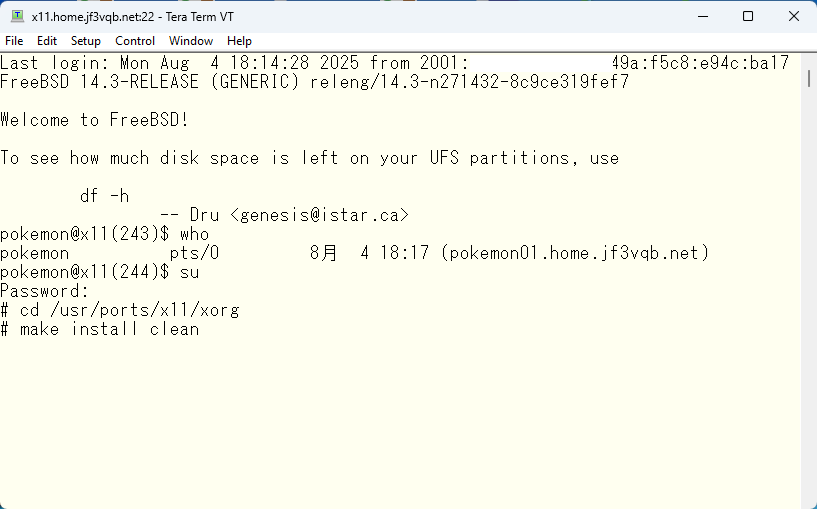
こんな感じで終わっていれば大丈夫だと思います。比較的大きなソフトウェアなのでコーヒー2杯は飲めるかな?
続いて X11 で日本語を扱うツールをいくつかインストールします。有名どころはいくつかあるのですが、私は Canna を使うことが多かったのでこれを使ってみます。
このように終わっていれば OK と思います。
インストール後に自動起動のための設定を追加するようにメッセージが出てきていますので、そのようにリソース変数を追加します。
かな漢字変換のエンジンはこれで自動起動するのですが、エンジンと X11 の間の通信を受け持つツールもインストールします。
インストール時に X リソースを設定するように言われますが、これらは Canna 用のリソースではなく Wnn 用のリソースに関してなのでここでは無視しておきます。
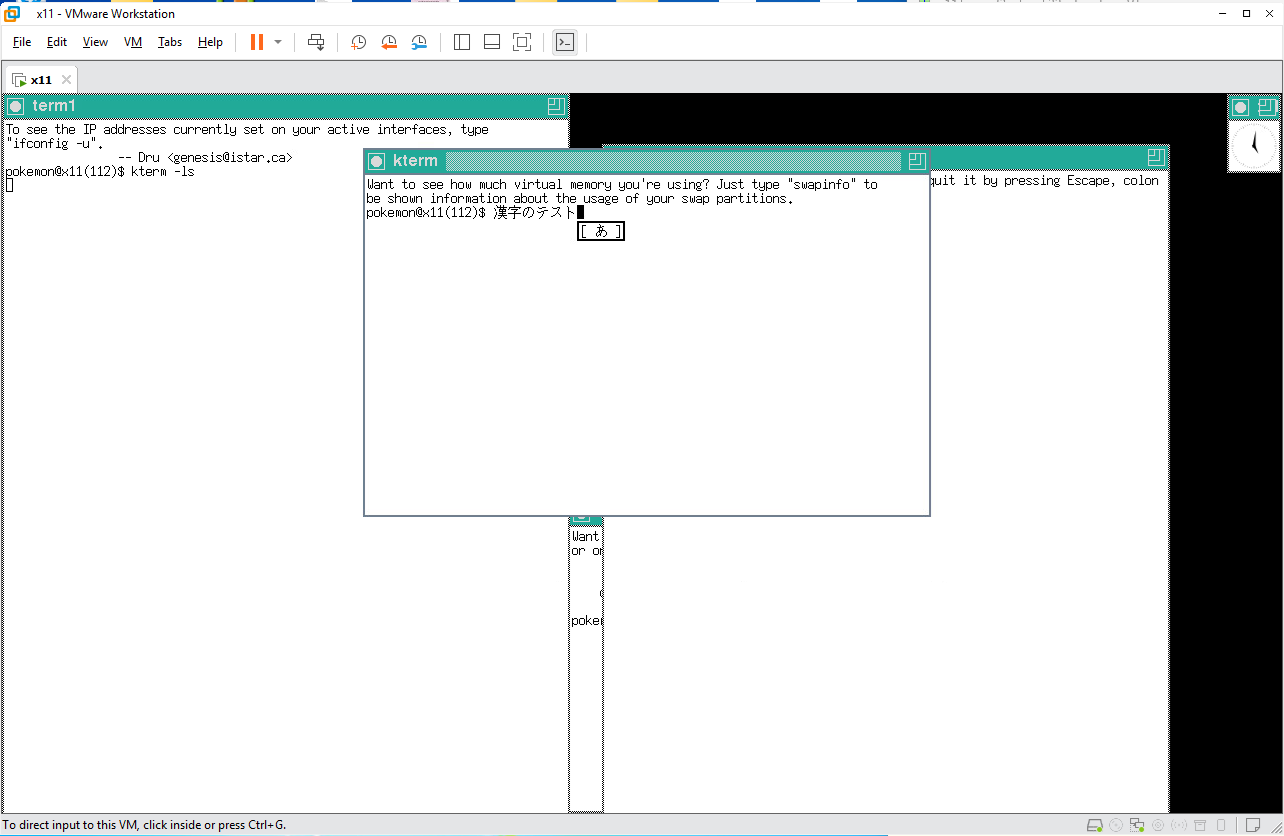
続いて、X11 で有名どころのターミナルエミュレータとして xterm がありますが、残念ながら kinput や canna を使用することができません。そこで xterm と互換性があり、日本語のハンドリング機能を追加した kterm を使用することになります。
このように完了していれば OK と思います。
さて、一通り日本人になるために必要なツールはインストールされたはずなので、X11 を vmware のコンソールで動かしてみます。
xterm がいくつか動いているだけのデフォルトのデスクトップが表示されました。
日本語を UTF-8 で扱う準備ができていることを確認するために環境変数をチェックします。
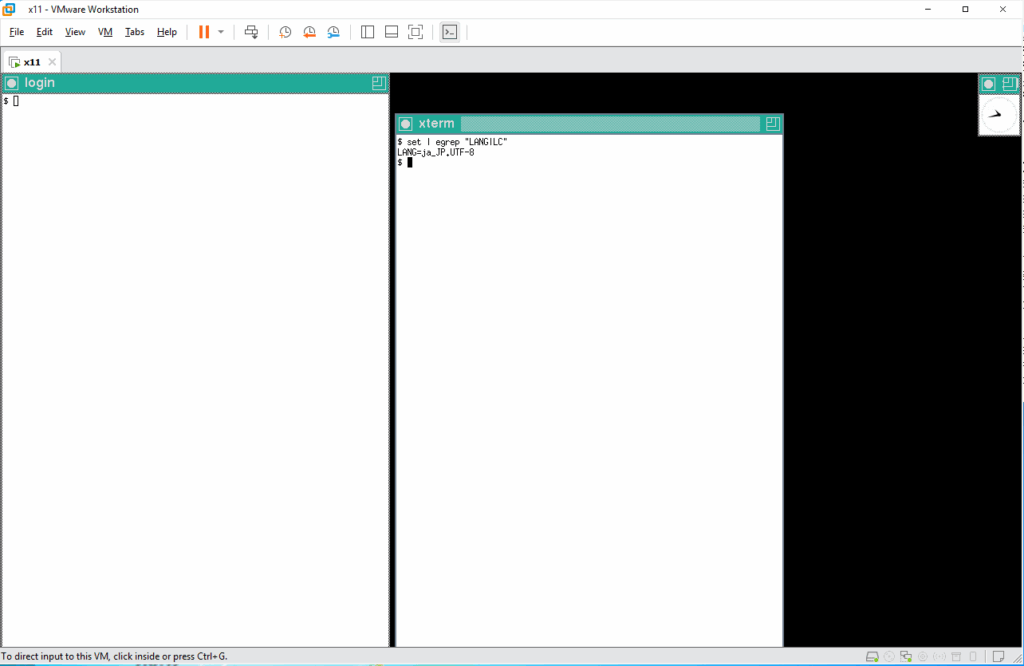
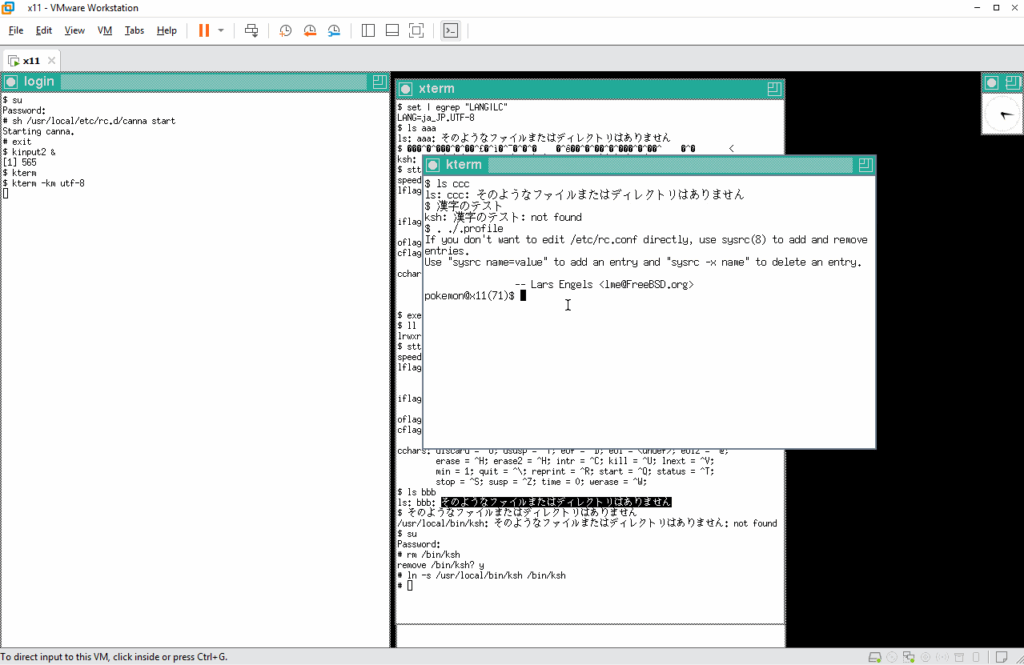
確認出来たら、実際に動かしてみます。まず、手始めにファイル aaa の有無を確認しますと、そのようなファイルは無いと言われます。表示されたメッセージをコピペしてコマンドとして入力してみます。
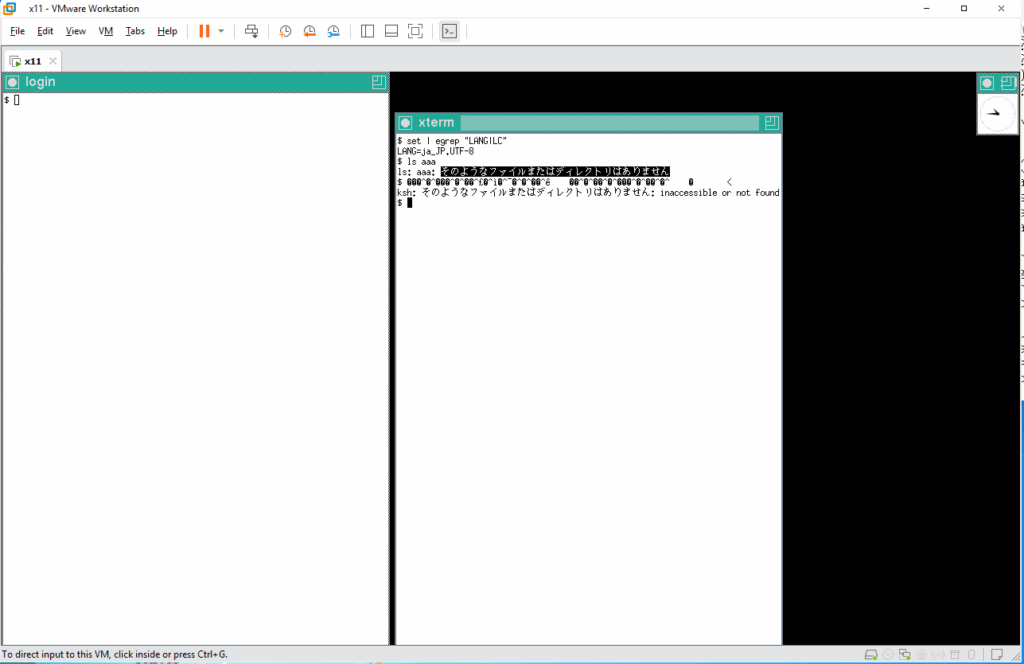
シェルからのエコーバックがバケバケになっています 🙁 問題点を特定します。まずは tty ドライバへのパラメータが正しく渡されているかを確認します。
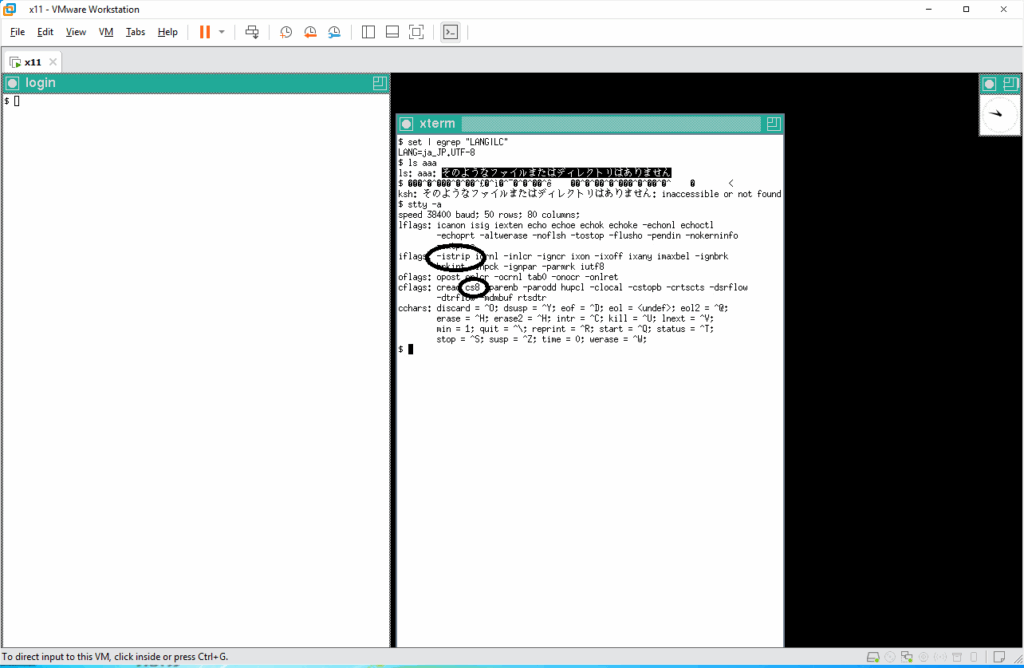
入力された8ビット文字はそのまま表示されるようになっています ( -istrip および cs8 )。では使用しているシェルが8ビットクリーンでない可能性がありますので調べてみます。現在 /bin/ksh は /usr/local/bin/mksh へのシンボリックリンクです。
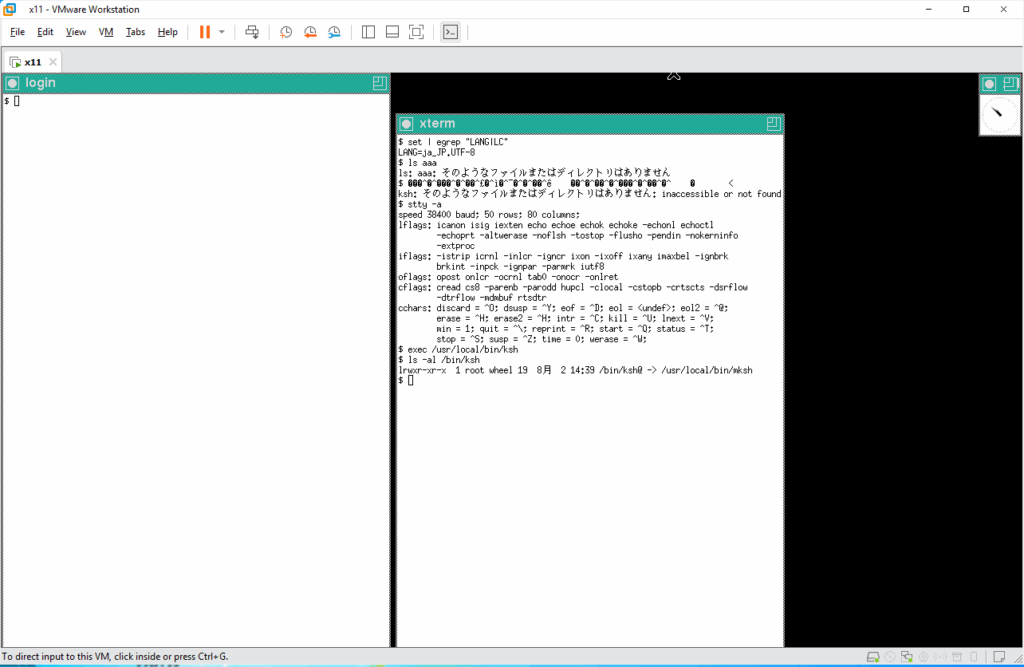
この mksh ( /usr/local/bin/mksh ) を pdksh ( /usr/local/bin/ksh ) に変えてみます。
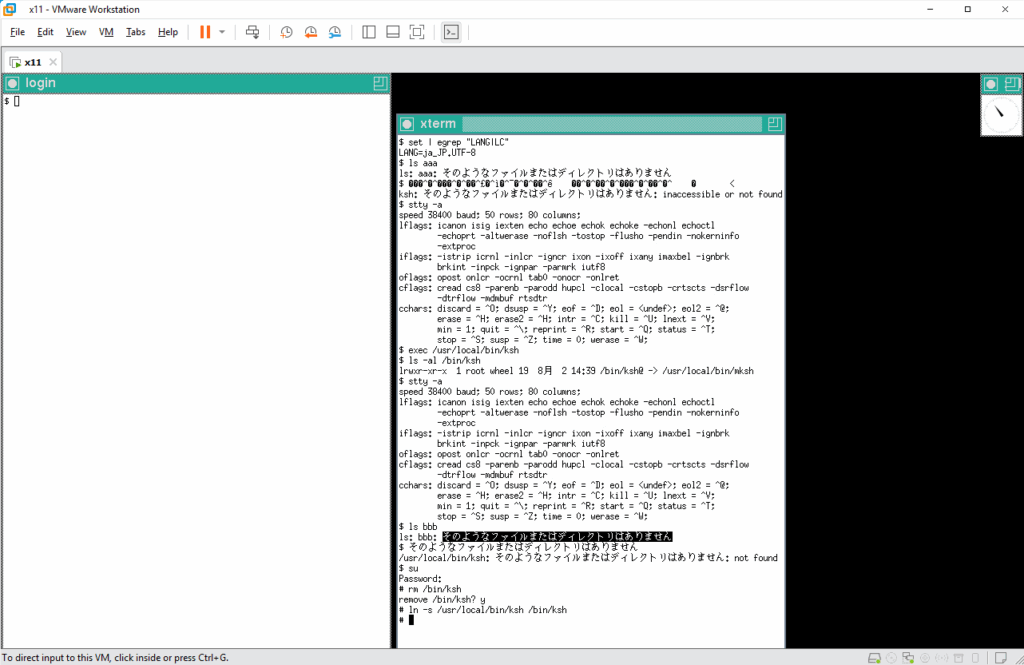
エコーバックも入力した通りに見えます、ということで pdksh は8ビットクリーンのようなので、シンボリックリンクを作り直して、デフォルトのログインシェルを mksh から pdksh へ変更しておきます。そして、かな漢字変換エンジンの canna を起動ます。
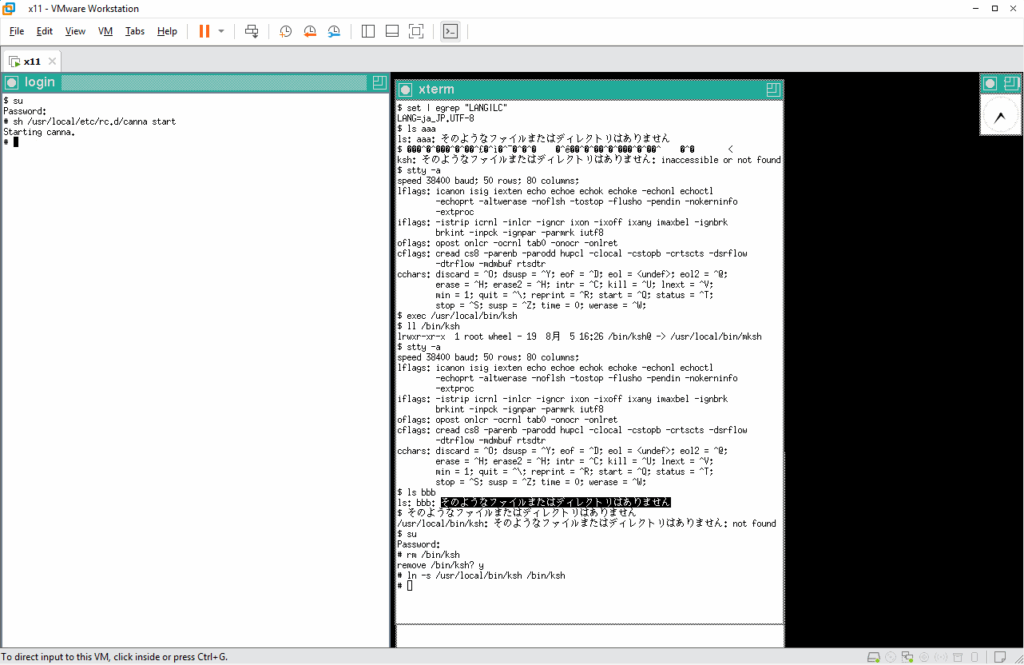
そして、kinput2 を動かして、X11 からかな漢字変換エンジンを使えるようにします。
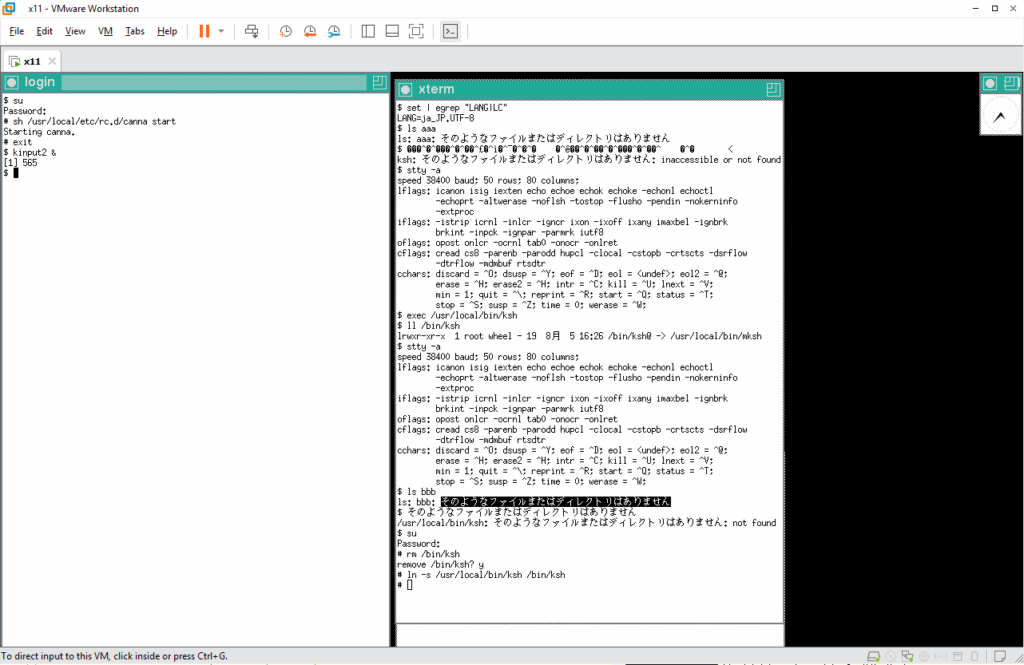
まず、kterm を起動します。
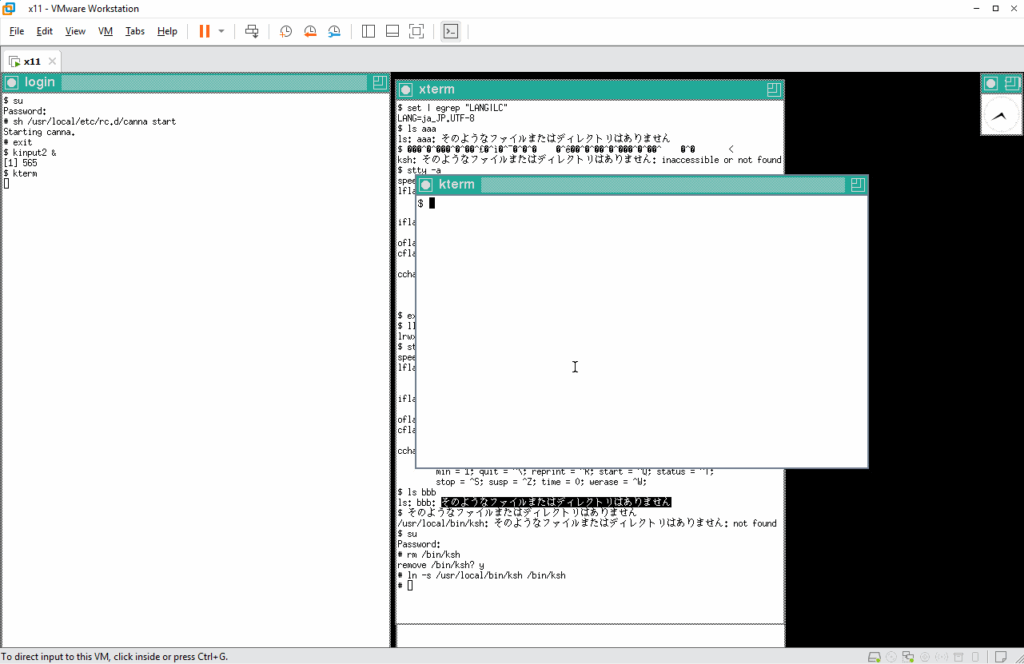
kterm 上でファイル ccc の有無を確認したところ、ファイルはリストされずにメッセージが表示されています。たぶんファイルは無いことを表すメッセージと思われますが、文字化けしています。
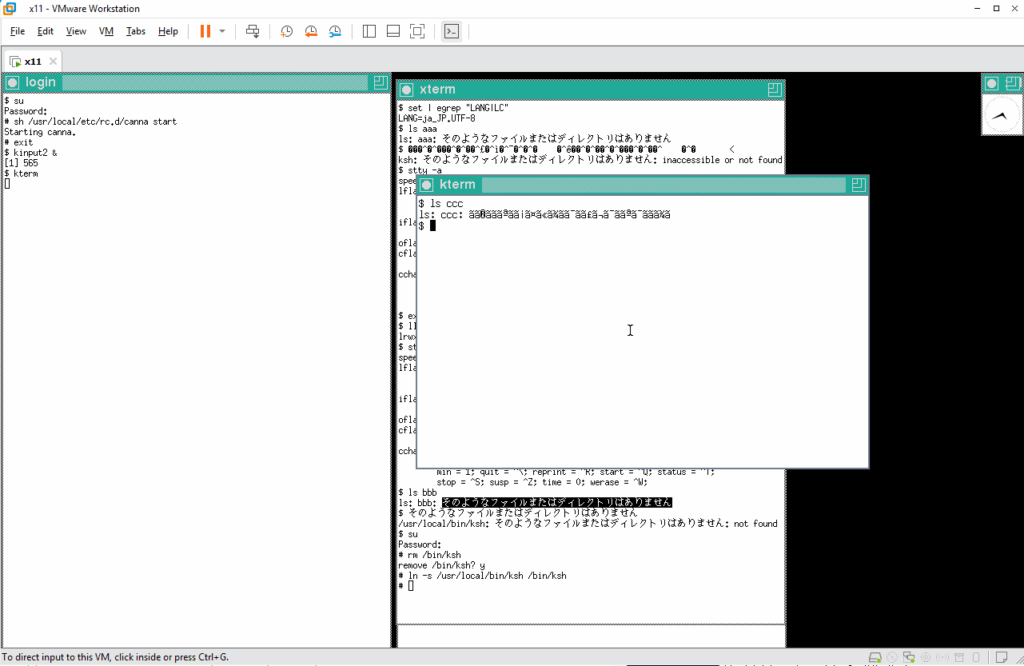
日本語メッセージが出力されるようになっているか確認します。
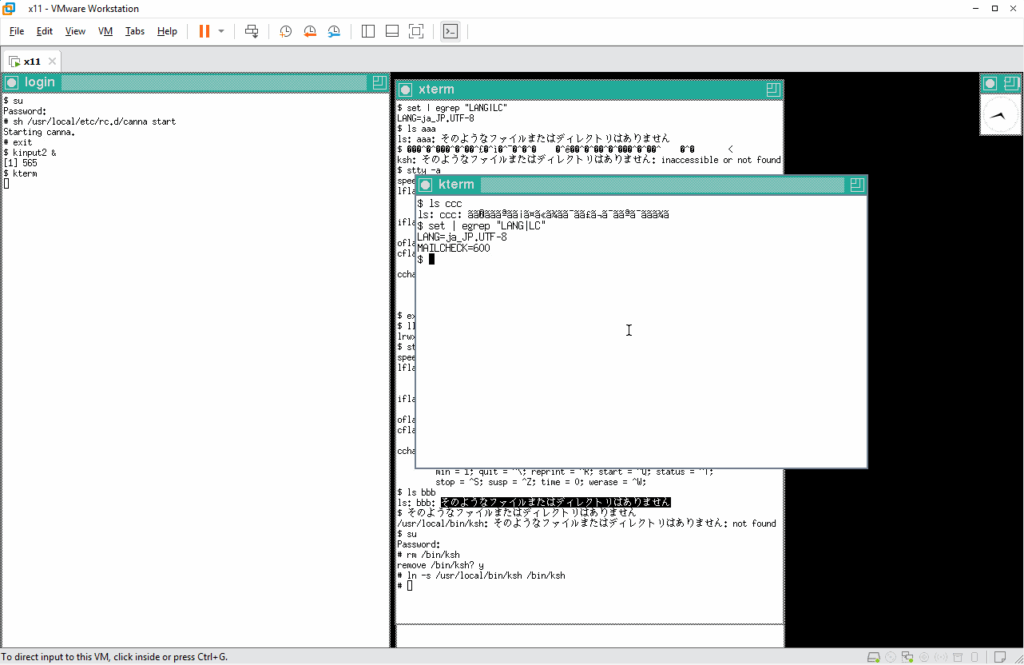
手がかりを求めてマニュアルを見てみます。
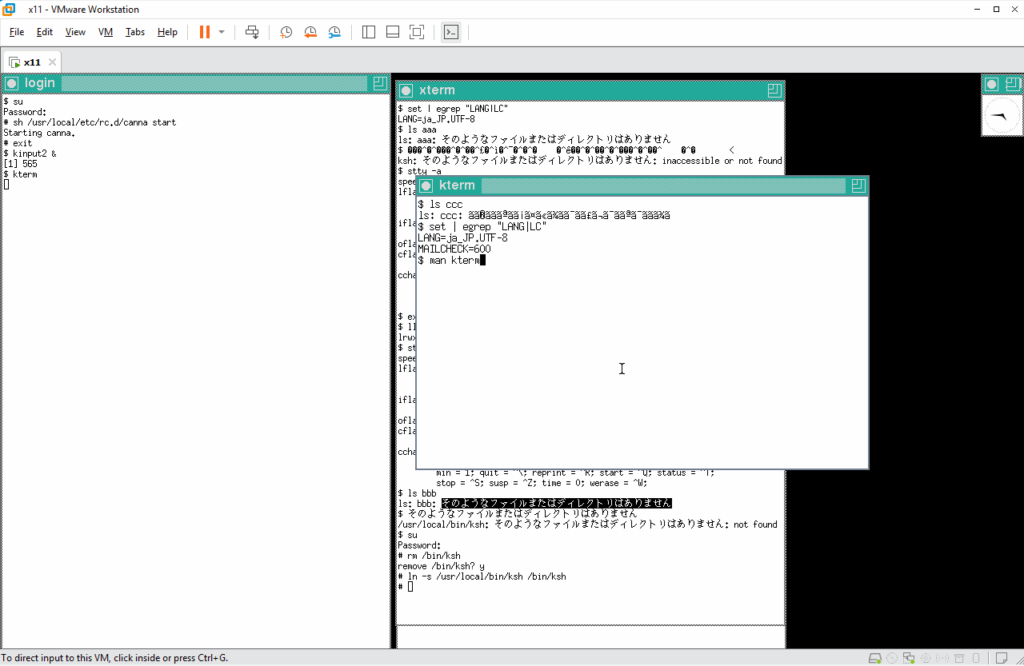
日本語マニュアルが利用できるようですが、このマニュアルも化けています 🙁
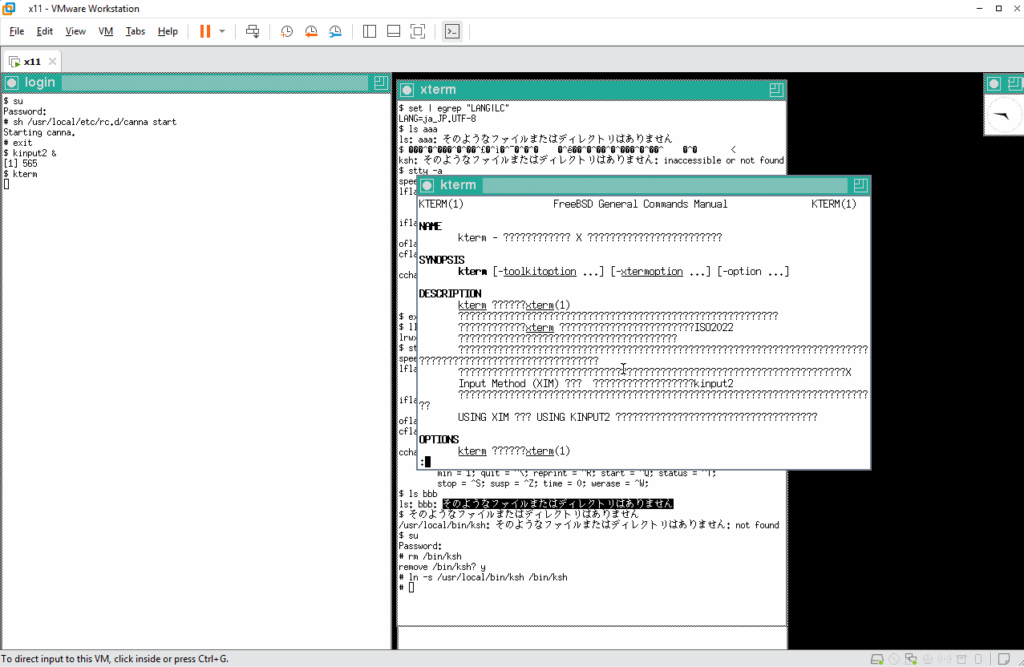
この問題は後で直すとして、とりあえず英語のマニュアルで手掛かりを探します。
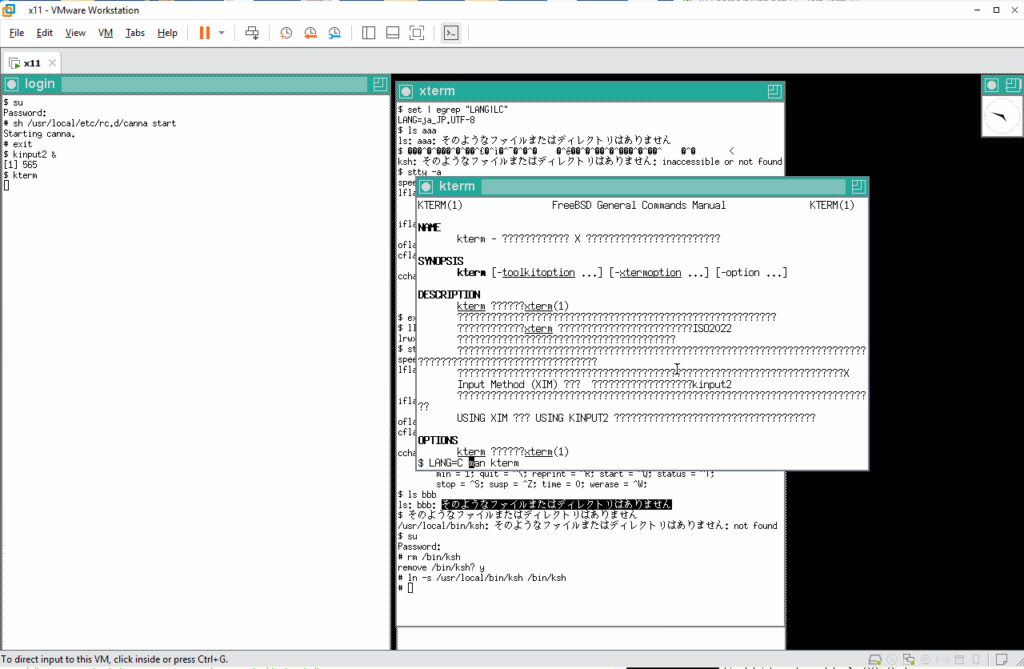
マニュアルページを読み進めてゆくと、使用する漢字コードに関しての記述があります。
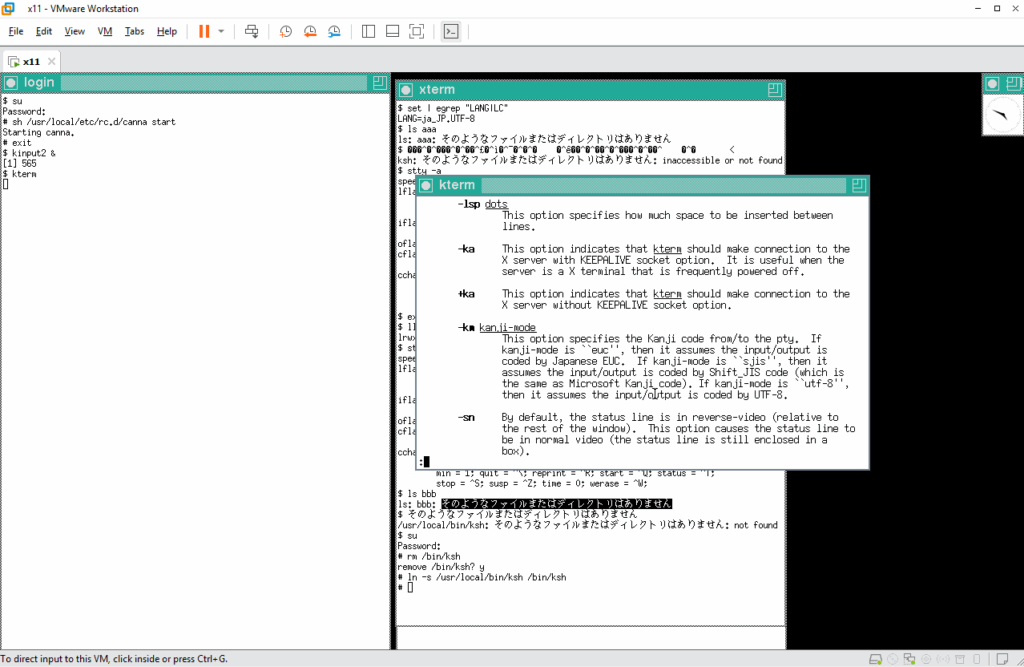
LANG 変数は UTF-8 を使用するように指定されていたので、kterm の漢字コードも UTF-8 を指定して起動しなおします。
8ビット文字の入出力の問題は解消されたようなので、日本語ハンドリングのメインパートであるかな漢字変換エンジンの動作確認を行います。ローマ字入力は大丈夫のようです。
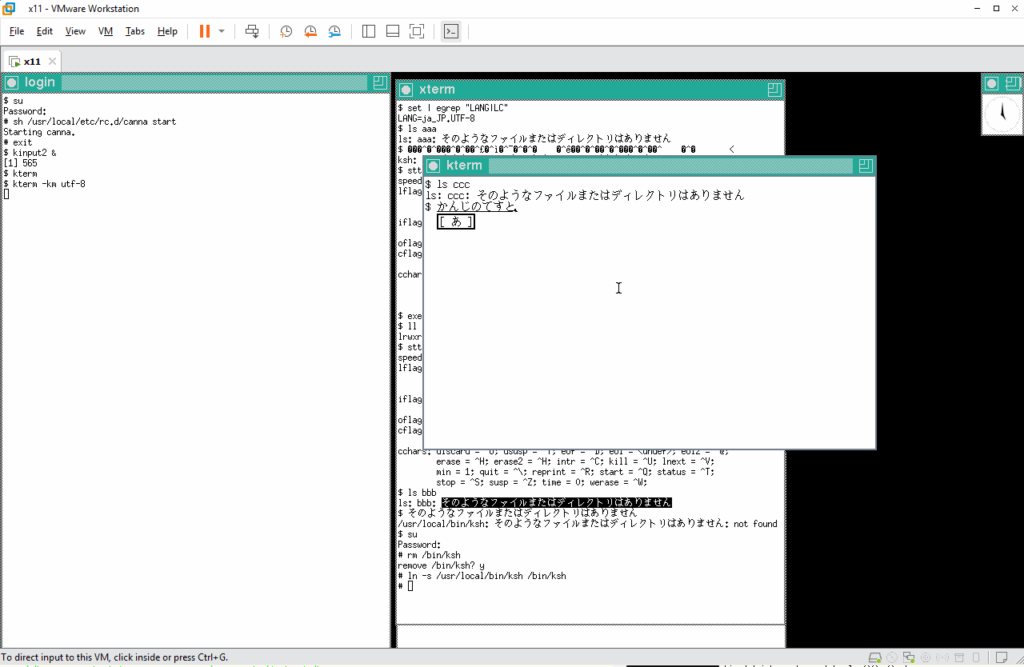
スペースキーを押して変換してみます。これもよさげです 🙂
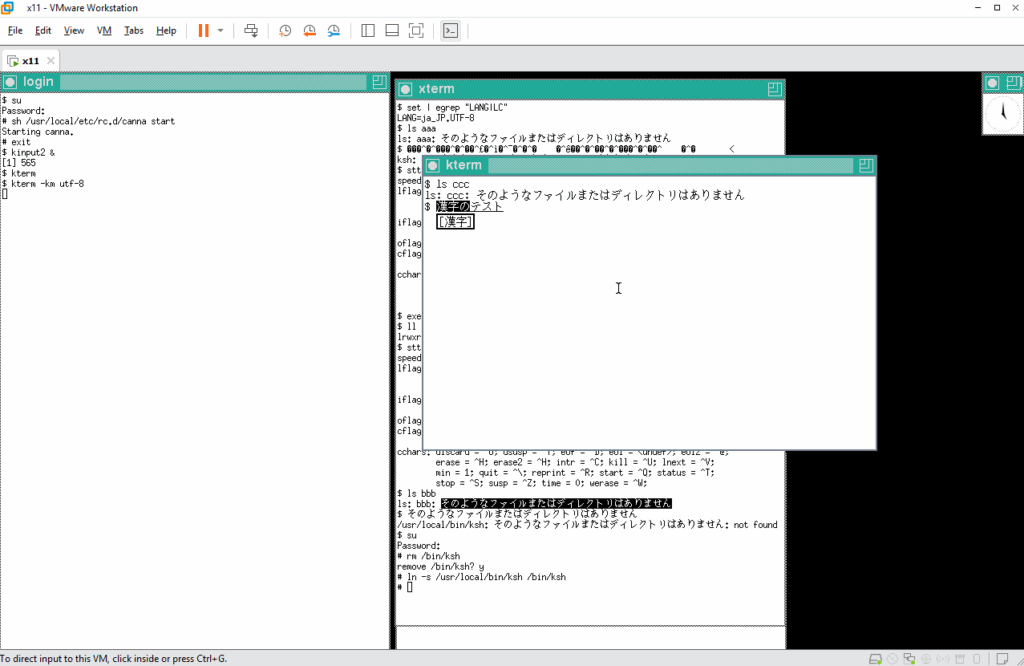
変換候補をリストしてみます。
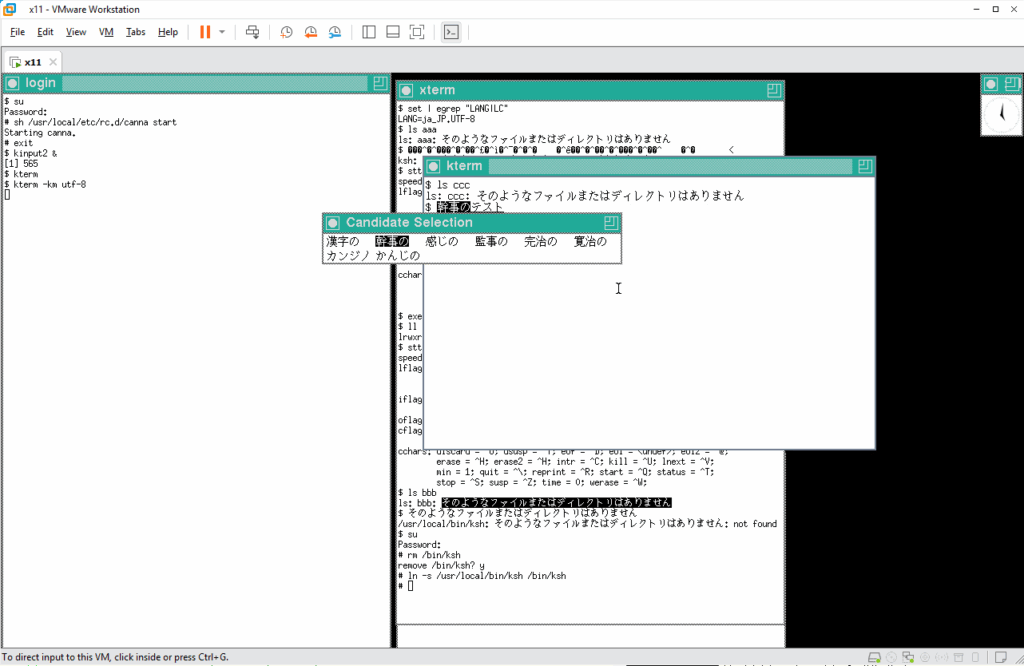
期待通りに動いてくれたので、シェルに対して変換された文字列を渡します。
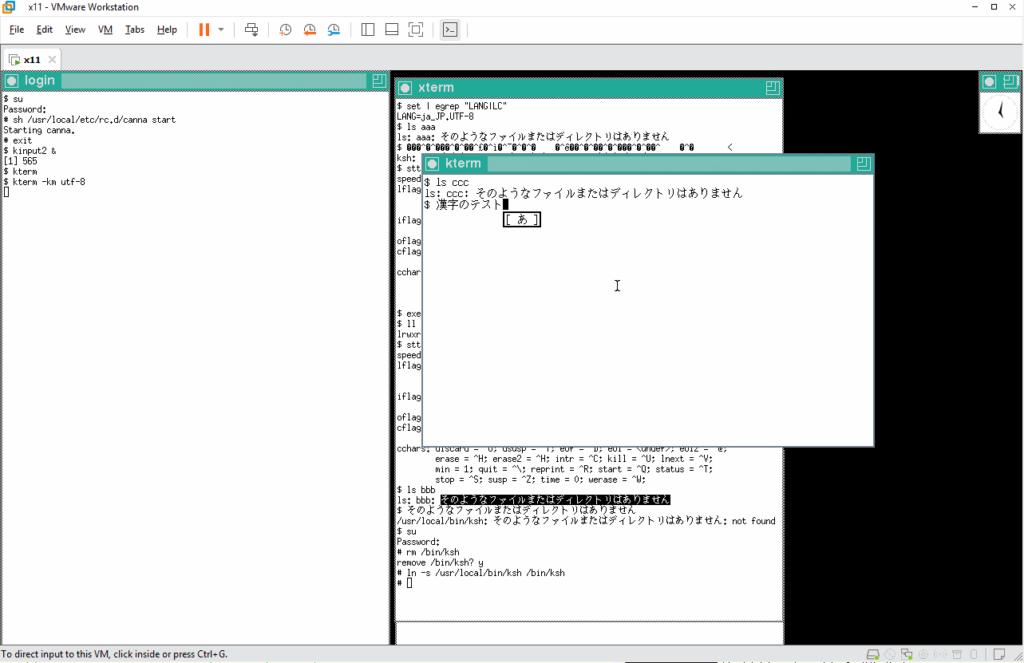
エコーバックの問題もなく期待通りに動いているようです。
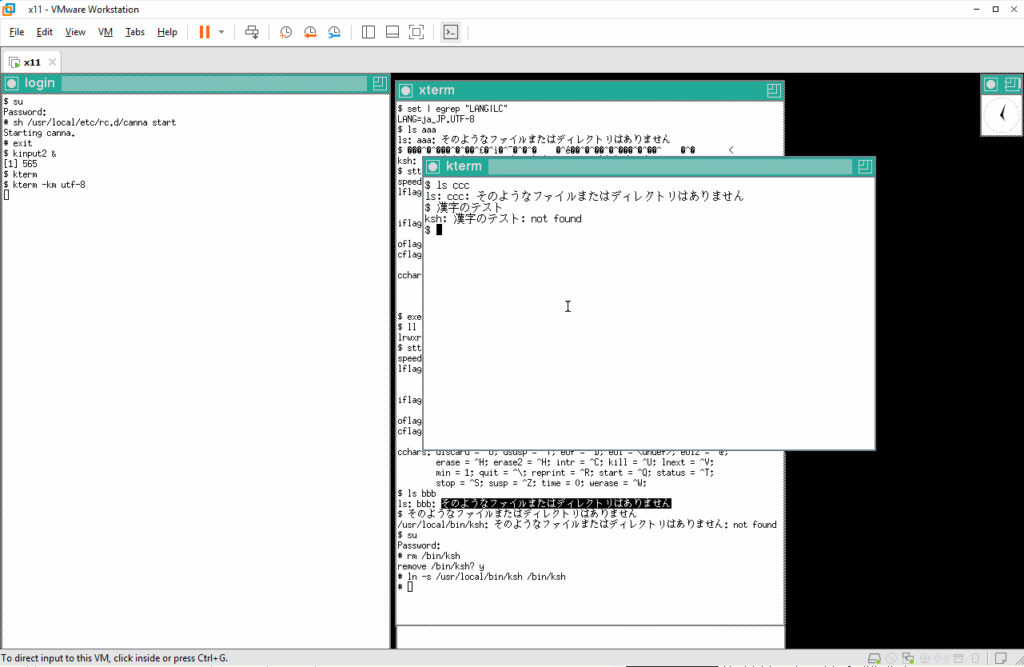
どのような状態なのかがわからないので、シェルにプロファイルを読み込ませます。こうでなくっちゃ 🙂
おおむね大丈夫のようなので、見つかった問題点を直してゆきます。まず、kterm の日本語マニュアルが化けてしまう件から直してゆきましょう。
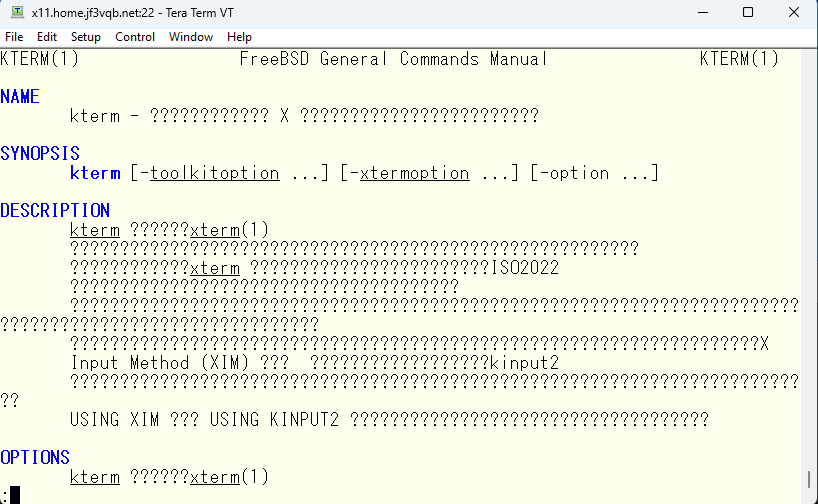
手がかりを探すために kterm のソースコードを見てみます。
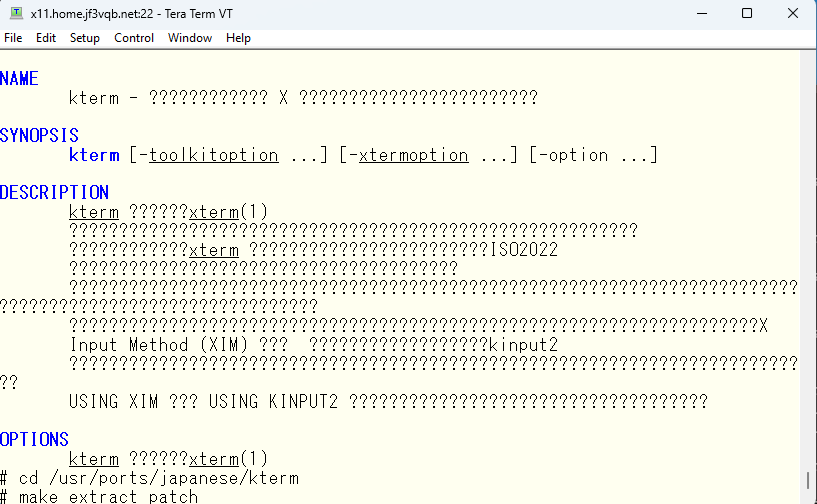
ソースコードの展開時にマニュアルページを触っているようには見えませんので、ビルドしてみます。
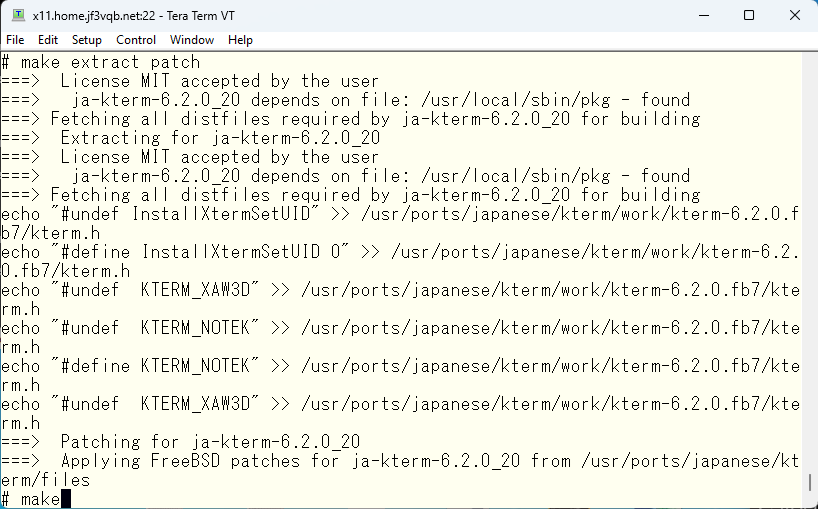
一番最後に日本語マニュアルをステージングエリアにコピーしているのがわかります。
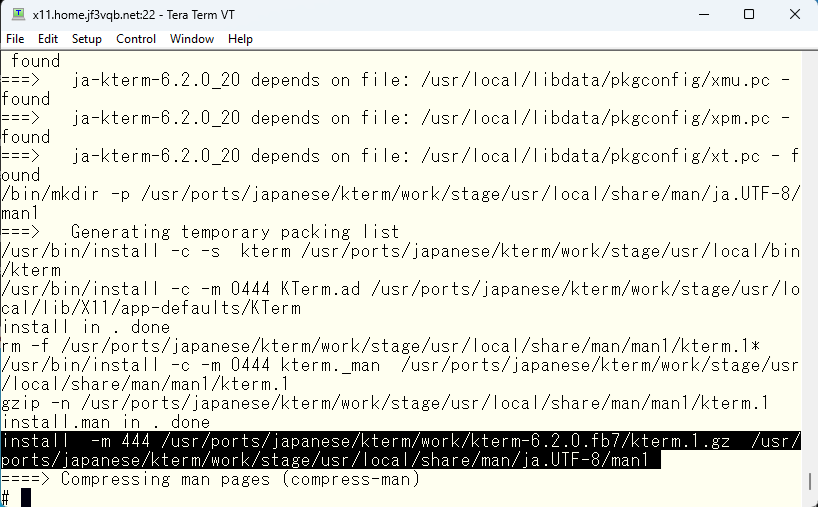
では、そのコピー元のファイルは大丈夫なのか確認してみます。
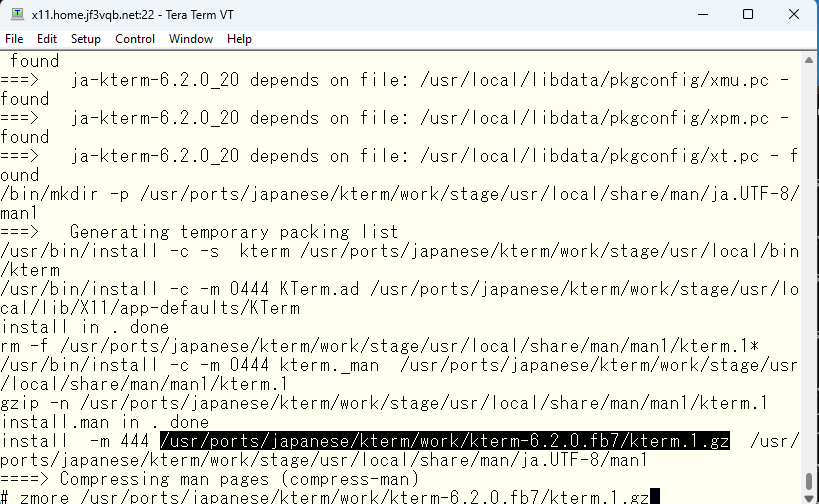
れれれっ 🙁 元がバケバケです。
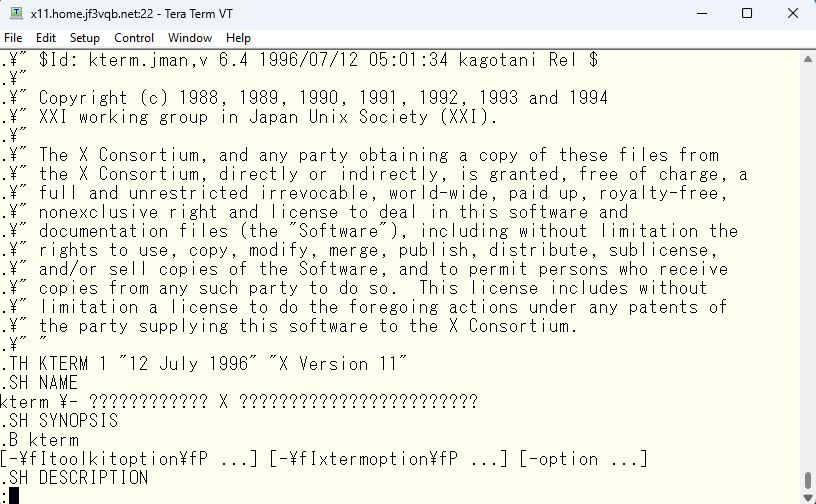
では、元のファイルがどのように作られているのかを見てみますと、このようになっていました。
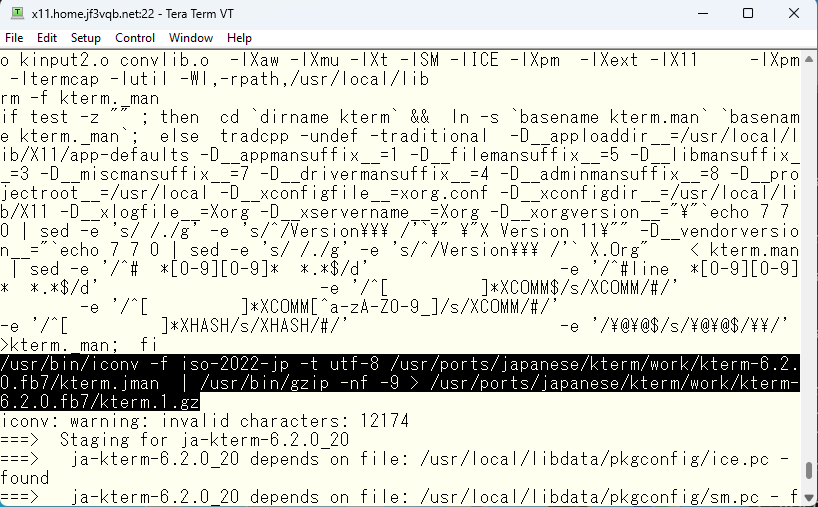
元ファイルを作るための、元々のファイルを見てみます。
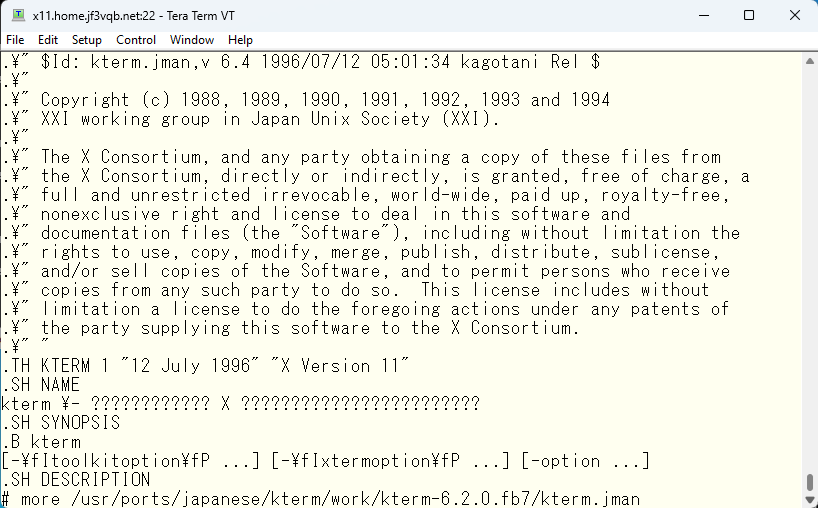
おぉ!元々のファイルは大丈夫なようです。では何が問題なのか?
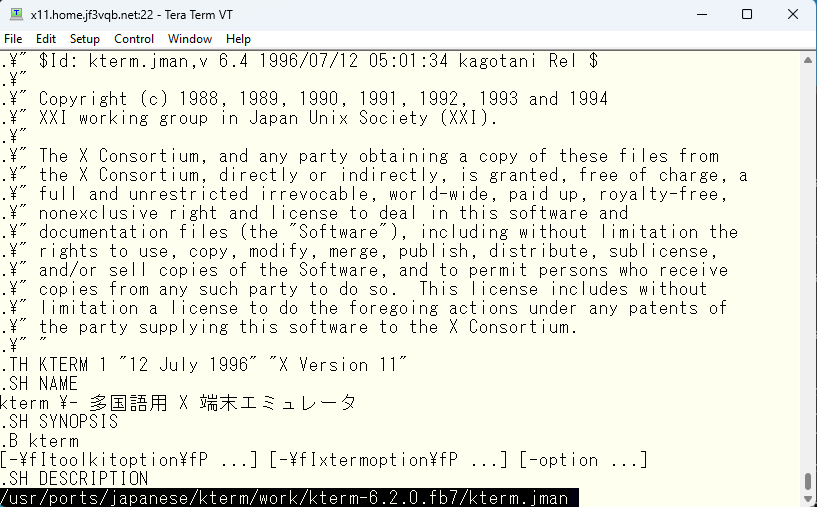
iconv コマンドで漢字コードを変換して作っていることから元々のファイルの漢字コードを調べてみます。
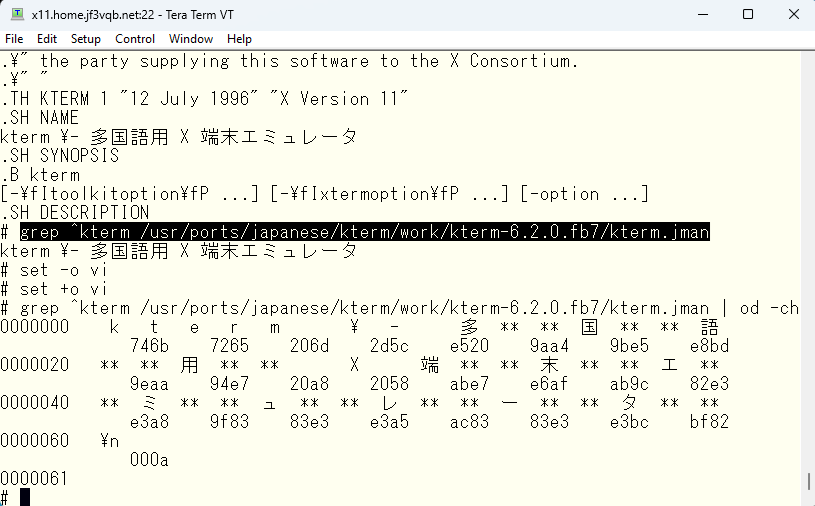
先の iconv による変換コマンドは、入力として ISO-2022-JP ( JIS コード ) を期待しています。ところがこの od コマンドで得られる出力より、明らかに JIS コードではないことがわかります。では何なのでしょう?一部分を切り出して file コマンドで見てみます。
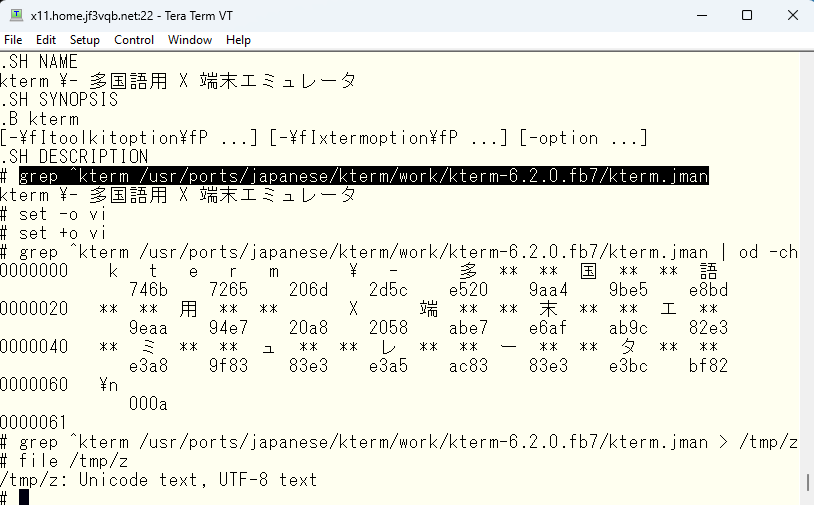
file コマンドによると、元々のファイルは UTF-8 であるようです。従って、先の iconv コマンドによる変換は不要であることがわかります。ですので、手動で元々のファイルを圧縮だけして、ステージングエリアにコピーします。
ここまでで、make が完了した状態のはずなので、kterm をこのまま再インストールします。
では、環境変数を確認しておもむろに日本語マニュアルを見てみることにします。
OK ボクジョー!!
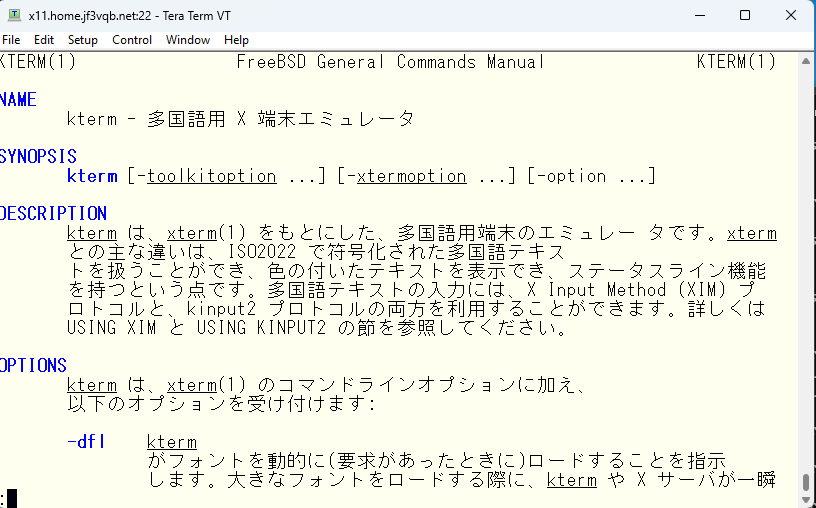
環境変数をリセットして英語版のマニュアルも見れることを確認しておきます。
これも OK 牧場!
では、X11 を立ち上げてみましょう。トッテモシンプルなデスクトップなのですが、どこで定義されているでしょうか?
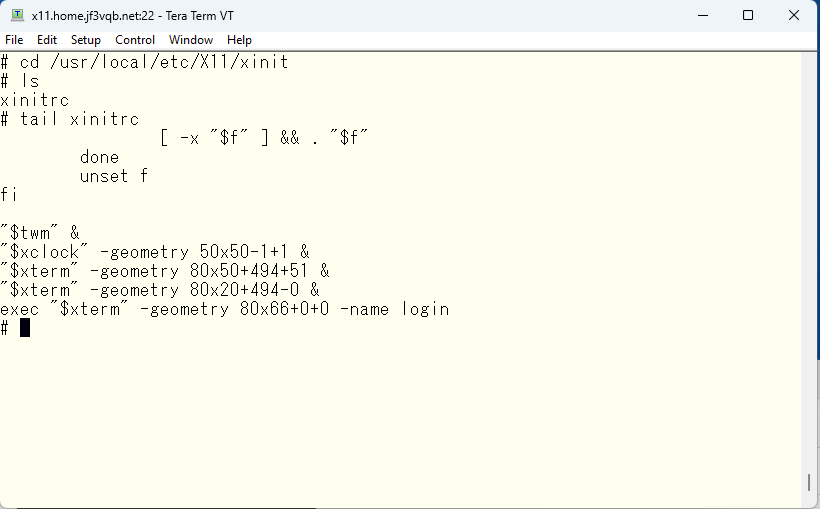
X11 を起動すると、UN*X の init と同じように xinit が最初に起動されます。xinit は xinitrc ファイルに記述されている通りにデスクトップを作り上げます。こちらが xinitrc ファイルの最後の方です。えっ?xterm の数が違う?
デスクトップが狭すぎて重なっているだけです。ちょっと xterm ウィンドを動かしてみるとその下にもう一つあることが見えます。
もう少し実用的な初期デスクトップにするにはどうしたらいいでしょうか? man xinit で確認できます。ホームディレクトリに .xinitrc というファイルでカスタマイズすることができます。オリジナルの xinitrc をホームディレクトリにコピーして自分の好きなように編集してカスタマイズしてゆきます。
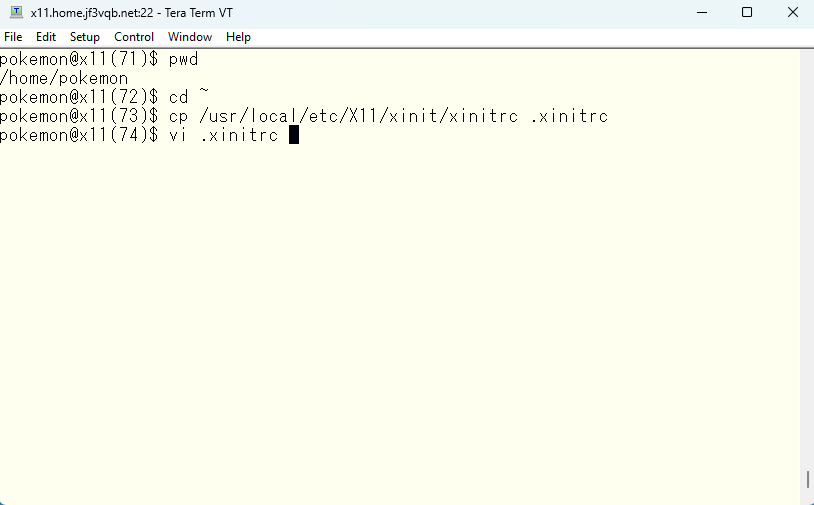
このようにしてみました。ファイルの先頭の方で、xterm 変数に kterm をセットするようにしています。
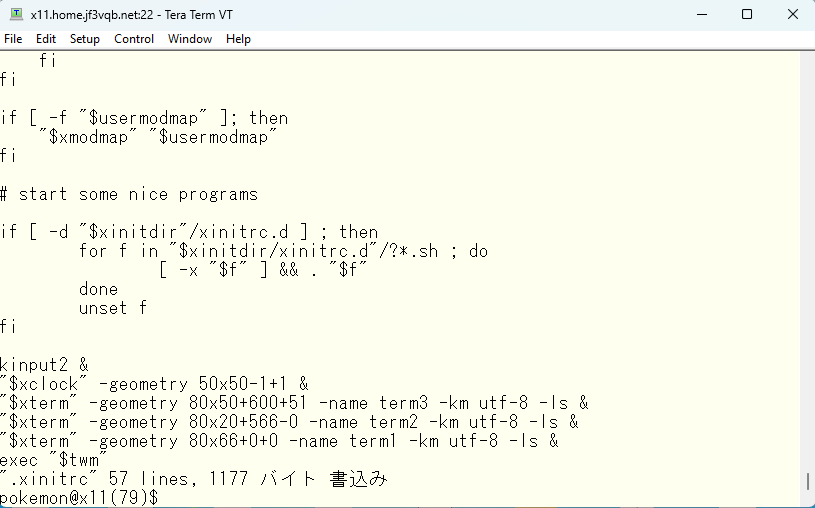
ちょっとマシになりました 🙂
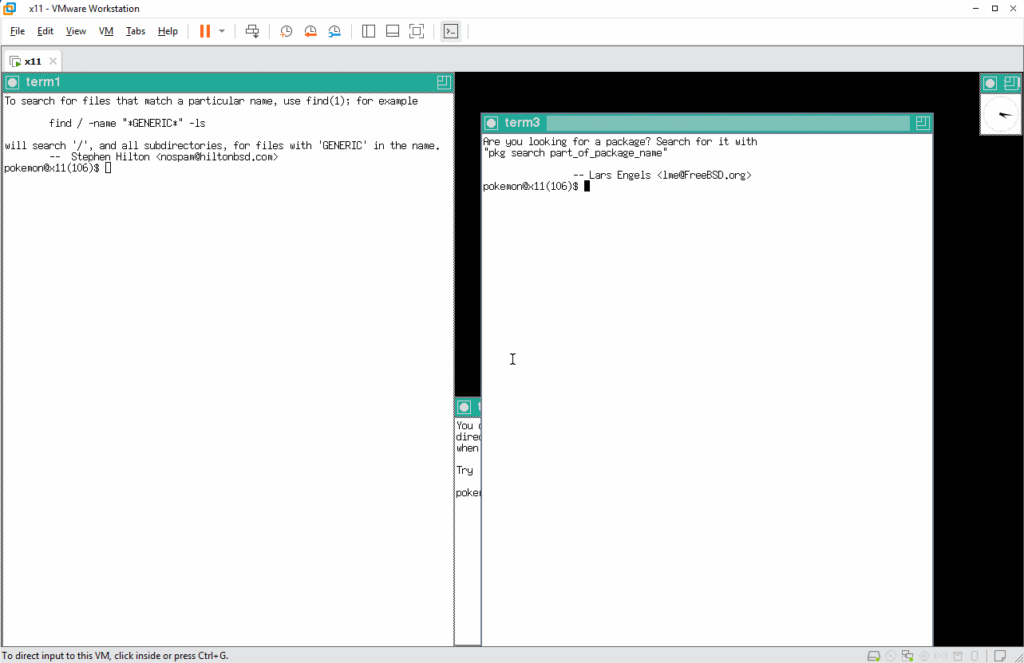
初期状態で、プロファイルも読み込まれていますし、かな漢字変換も動くようになっています。もうこれで何でも動かすことができますね 🙂 使いたいツールがなければ /usr/ports 配下でビルドして使えるようにしましょう!でも、ここにきて新たな問題に気づきました。ネズミの運動場が狭すぎます 🙁
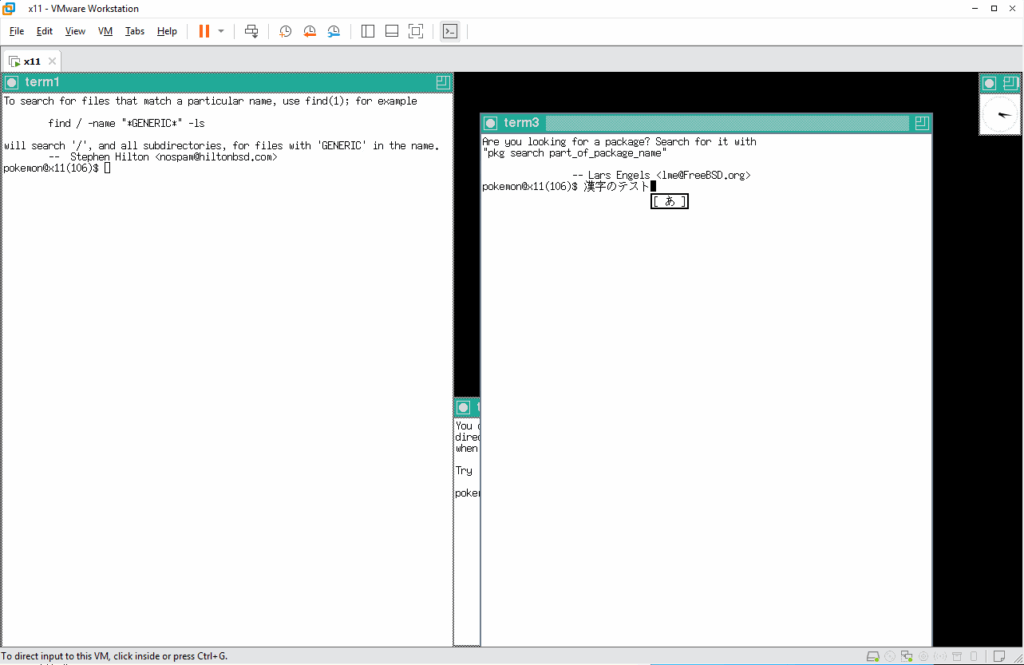
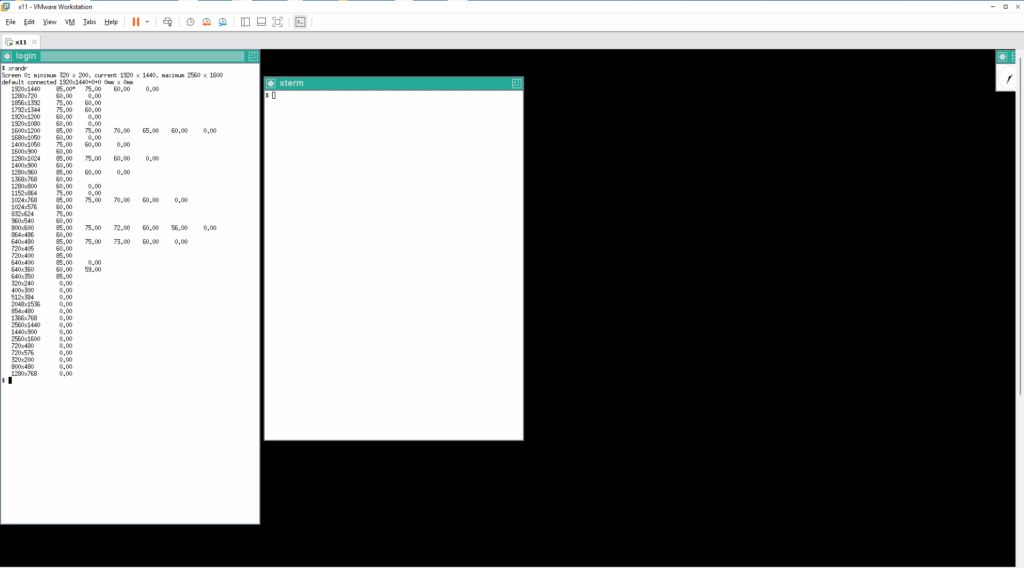
現在の運動場の広さを見てみましょう。xrandr コマンドを引数なしで実行すると、* が付いているモードで動いていることがわかります。この場合だと、1280×768 ドットモードとなっています。ここで使えるモードはどの GPU にでも共通に使用できるモードである VGA モードの範囲で利用可能なモードがリストされています。私が使用している DELL ラップトップの画面の解像度は 1920×1440 となっています。なので、ネズミの運動場もその大きさになってほしいと思うのですが、このままでは最大でも 1280×768 までとなっています。で、どうするかというと X11 サーバが直接動く PC で使用している GPU のドライバーをインストールすることで GPU の能力を最大限に引き出してくれます。
今回の場合は vmware コンソールのグラフィックドライバを入れることになります。
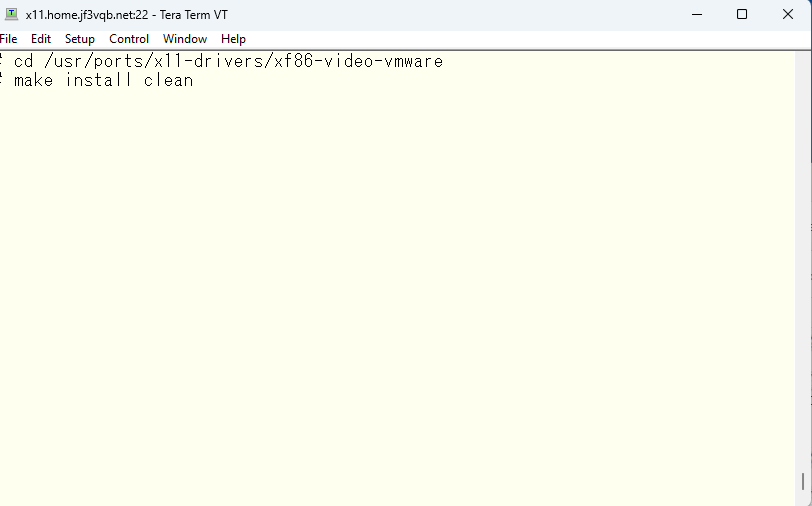
実機を使用する場合は GPU に応じた適当なドライバを使用するようにしてください。
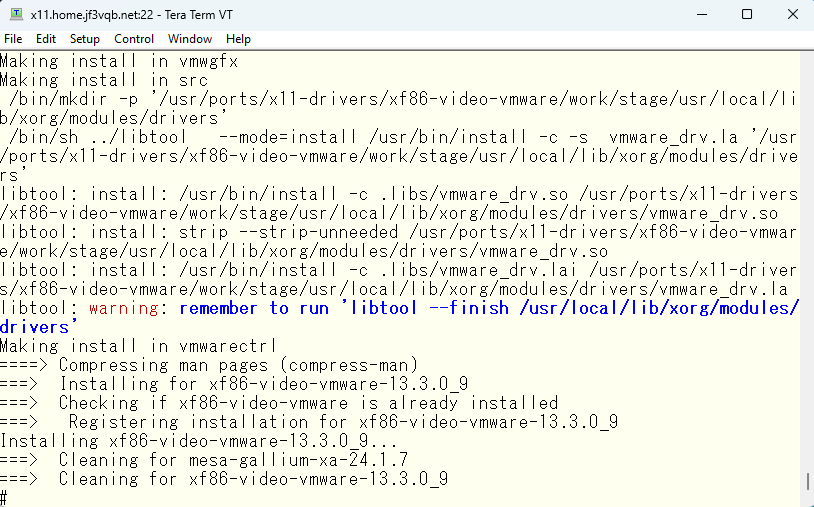
さて、この状態で X11 を動かしなおして、利用可能なモードを確認してみます。
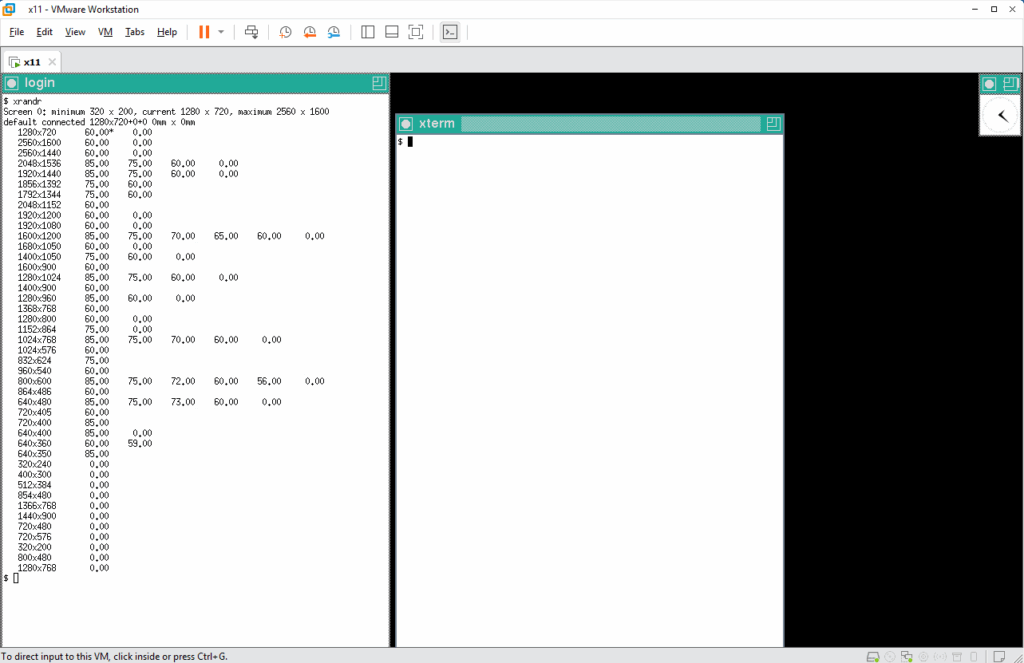
いい感じなので、PC と同じ解像度を xrandr で指定して実行してみます。画面が右方向と下方向に広がったので、xterm の表示が全て見えますし、xclock が画面の真ん中寄りにあるように見えます。
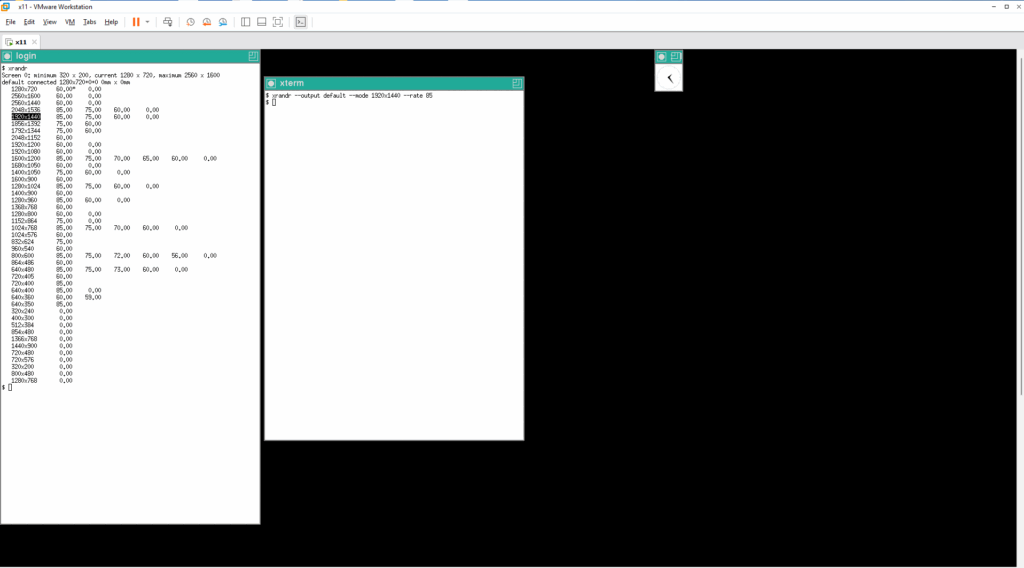
このモードをデフォルトにしたいので、グラフィックドライバの定義ファイルを作っておきます。
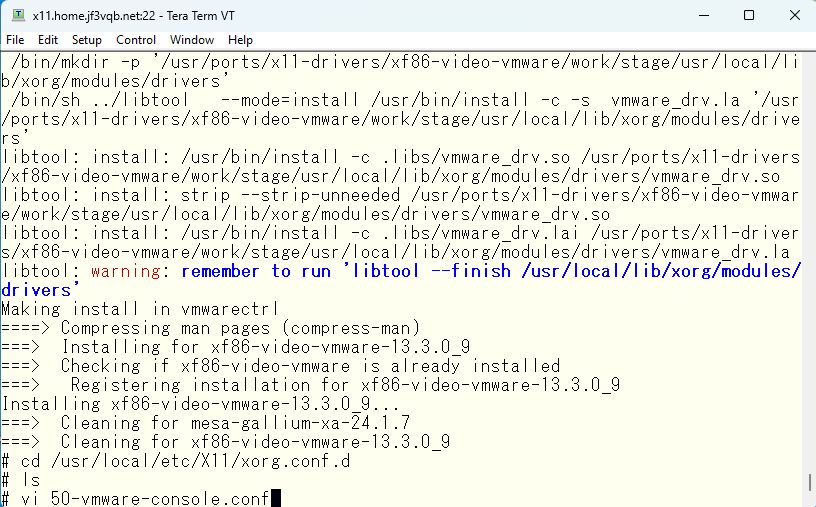
必要なオプションを書き込んでおきます。この情報は man vmware から辿ってゆきましょう。
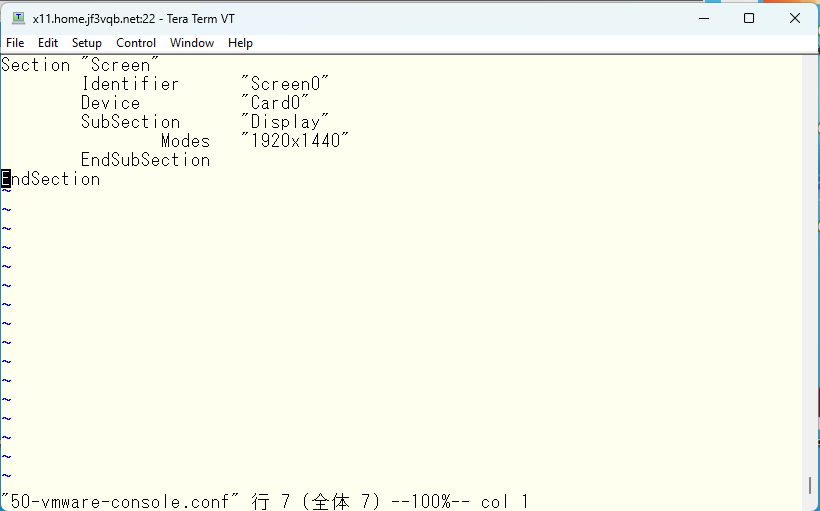
これで X11 を再起動してみます。いい感じです 🙂
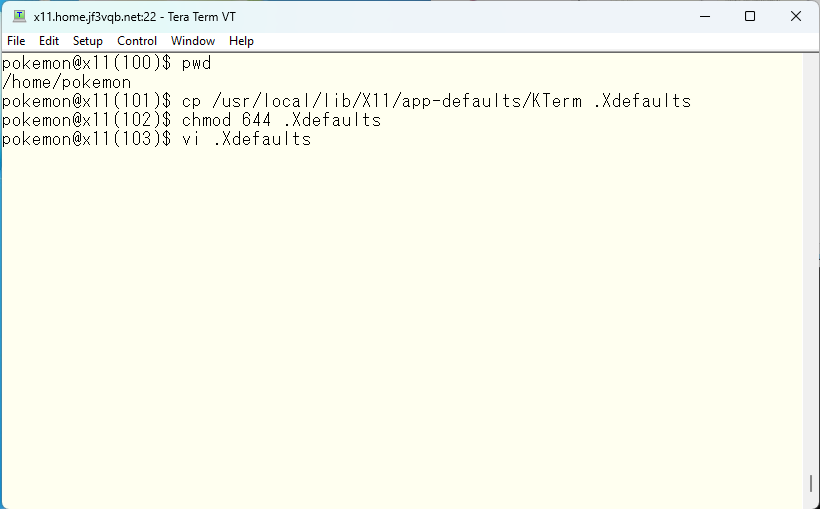
これでネズミの学校の校舎の配置も自由に変えることができるようになったし、運動場の広さも自由に変えることができるようになりました。最後に校舎の間取り ( 恐くはないです 🙂 ) を変更してみたいと思います。X11 の各アプリケーションにはリソースファイルがあり、デフォルト値が定義されています。カスタマイズしたいファイルをホームディレクトリの .Xdefaults ファイルにコピーして変更したい部分だけ再定義しておきます。複数のアプリケーションがある場合は複数のリソースファイルを1つの .Xdefaults に編集してマージしてゆきます。今回は KTerm だけなので、単にコピーします。
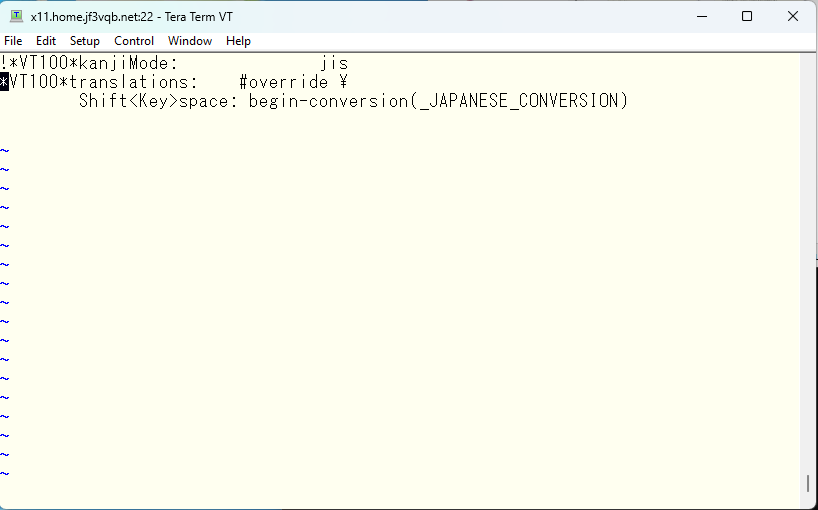
そして、変更したい行を残してそれ以外は消しておきます。
まず kterm を漢字コードを指定せずに起動してみます。そして、漢字をシェルに渡す準備をします。
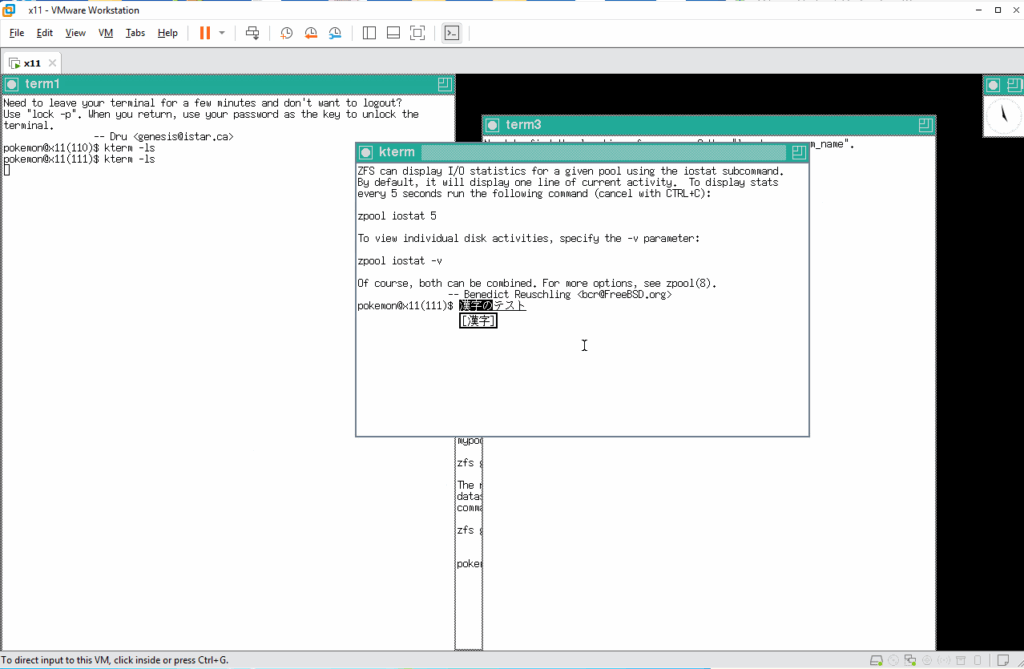
エンターキーを押して、変換された日本語をシェルに渡します。すると、またしてもバケバケになります。これもこれまでに見た化け方とはまた化け方が違います。
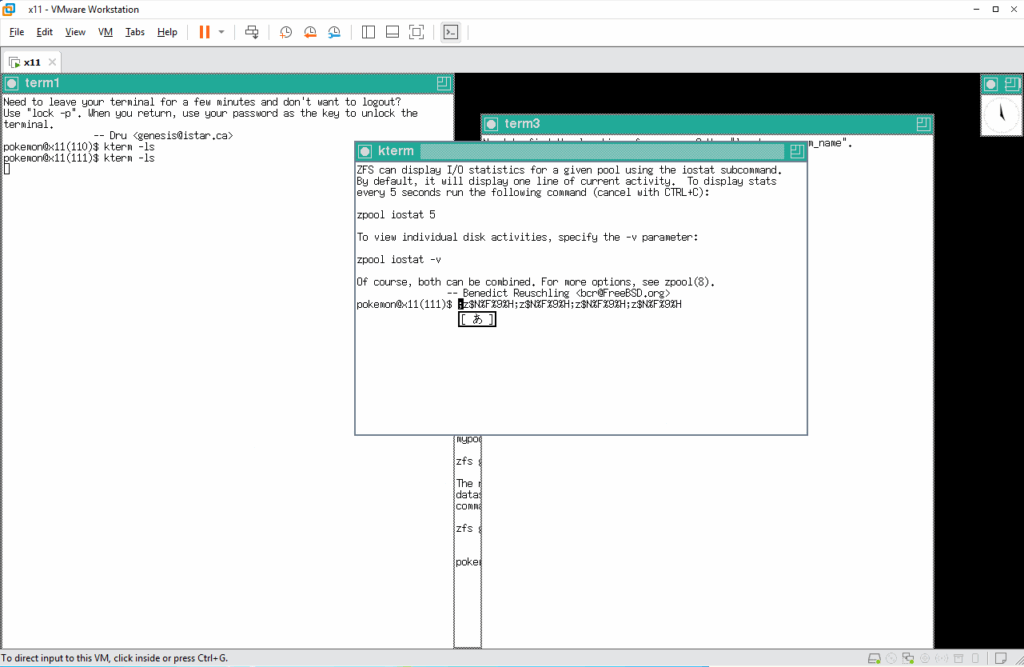
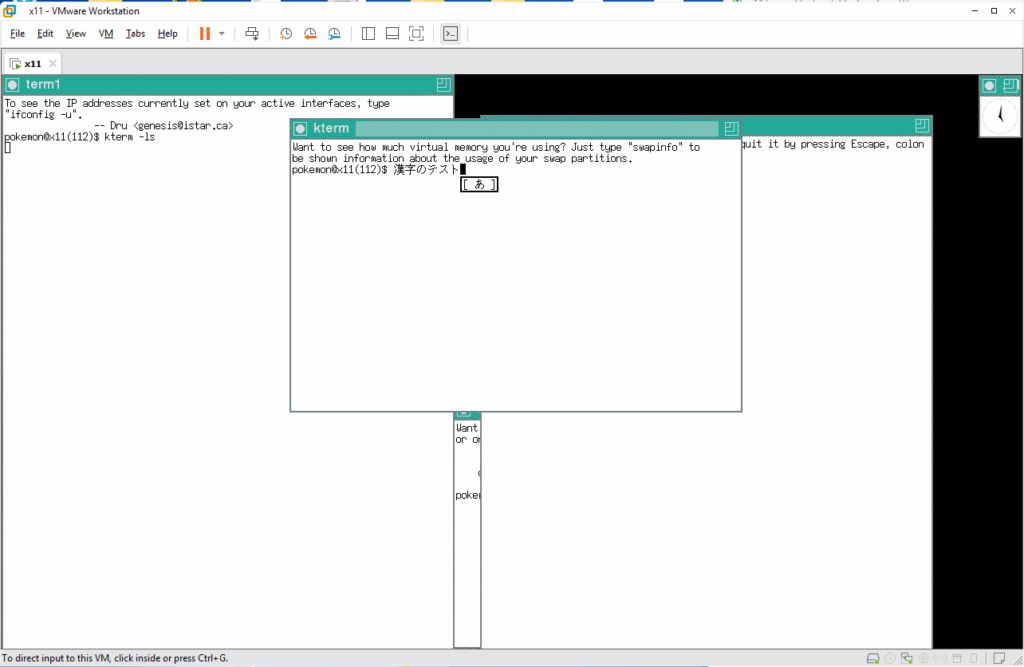
そこで先ほどのリソースファイルを見てみると、1行目で漢字コードを指定することができます。このままでは、コメント扱いなので、コメントを外して、漢字コードとして utf-8 を指定して同じ事をしてみます。
全部 OK 牧場!!!
一番最初に使用した X11 は、とある大学の先生より分けてもらった X11 のソースコードを MT から読みだして、何日かかけてコンパイルして動くようにしたものだったと記憶しています。X サーバーはどうしたかというと、今の様に高スペックなパソコンで動かすようなことはできず、X ターミナルと呼ばれる X サーバーを動かすことに特化したハードウェアを使用して、必要な設定やフォントなどは tftp や NFS で起動時にコピーしてきてネットワーク経由で X クライアントを表示していました。PC でいうところのディスクレスみたいな感じですね。お分かりとは思いますが、この構成だと M$ IME は使えませんので、kinput2 や Canna/Wnn 等は日常生活に必須でした。そのころから数十年経過していますが、大枠ではその当時の知識がそのまま役に立つようです。当然細部ではいろいろ進化しているのでしょうが 🙂
漢字コードに関して少しだけ触れておきたいと思います。まぁ日本語はややこしい文字体系です。大きく分けると4種類存在します。
| 漢字 コード | 特徴 |
| JIS コード | 全て 7ビット文字で構成されており、KI, KO 等のエスケープシーケンスで漢字部分とそれ以外を切り分ける。特に初期の sendmail が8ビットクリーンでなかったことから電子メールなどでよく使われることになる。 |
| Shift JIS コード | 古い時代の M$ 日本語 Windows で標準的に使用された漢字コード。非常に古い日本語ファイルなどを新しい Windows で開こうとすると文字化けすることがある。 |
| EUC コード | 古い日本語対応の UN*X でよく使用された漢字コード。 |
| Unicode | 現在ではほとんどの OS がこの漢字コードを使用している。よく UTF-8 として知られている。 |
またここに記した内容は X11 で日本語を扱うためのとっかかり程度の内容です。FreeBSD の X11 に関しては、The X Window System としてわかりやすく記述されていますので、んッ?と思ったらこちらをご参照ください。
![]()
![]()
